Versión: 1.0, Septiembre, 2005
Manuel Gómez Olmedo
Web: http://decsai.ugr.es/~mgomez, Mail: mgomez@decsai.ugr.es



| Versión: 1.0, Septiembre, 2005 Manuel Gómez Olmedo Web: http://decsai.ugr.es/~mgomez, Mail: mgomez@decsai.ugr.es |
|
Quizás convendría comenzar recordando algunos aspectos relacionados con el lenguaje Java de programación. Es importante saber que se trata de un lenguaje "interpretado". Es decir, no hay un archivo ejecutable que contenga las sentencias a ejecutar en formato completamente comprensible para la máquina; lo que ocurre en realidad es que las instrucciones se van traduciendo y ejecutando una a una.
Esto se debe a su deseo por ser "portable". Como un programa Java
debe poderse ejecutar en cualquier máquina (independientemente de
sus características específicas), el programa no debe contener
más que órdenes de "alto nivel" (no órdenes directas a
la arquitectura de la máquina). Obviamente, al final hay que generar
órdenes de "bajo nivel", pero de esto se encarga la
máquina
virtual de Java. Se trata de una aplicación que lee nuestros programas
específicos y realiza la traducción de órdenes de alto
nivel hasta órdenes de bajo nivel. Naturalmente, la máquina virtual
sí debe ser específica para cada tipo de arquitectura, ya que las órdenes
de bajo nivel generadas deben ser comprensibles por el sistema operativo que
vaya a ejecutarlas. Por esta razón hay herramientas específicas para LINUX,
Windows, etc.
Hemos de tener en cuenta que existe una creciente necesidad de disponer de aplicaciones ejecutable en dispositivos móviles. Para atender a esta necesidad Java ha desarrollado su plataforma denominada J2ME (Java 2 Platform Micro Edition). Esta arquitectura se basa en familias y categorías de dispositivos. Una categoría define un tipo particular de dispositivos: teléfonos móviles, organizadores personales (pdas), buscapersonas, etc. A su vez, la familia se compone por un grupo de categorías que presentan requisitos similares de memoria y de capacidad de procesamiento. La relación entre categorías y familias puede apreciarse en el gráfico siguiente:

La versatilidad es un objetivo primordial de J2ME, ya que hoy no se puede predecir el tipo de dispostivos que habrá de aquí a unos años. Por tanto, la plataforma de desarrollo ha de ser completamente escalable, de forma que la aparición de nuevos tipos de dispositivos no se traduzca en que las aplicaciones para dispositivos "antiguos" no puedan ser mantenidas. Para conseguir la escalabilidad, la arquitectura de J2ME se estructura en tres capas:

Veamos cuál es el objetivo de cada una de las capas:
Teniendo esto en cuenta,CLDC es la herramienta básica sobre la que se construyen los perfiles de J2ME para dispositivos móviles. Es decir, se trata de una configuración específica para dispositivos móviles. Estos dispositivos, como es bien sabido, disponen de limitada capacidad de procesamiento y almacenamiento (aunque se avanza continuamente para aumentar estos recursos). Esta limitación de espacio de almacenamiento y de capacidad de procesamiento hace imposible ejecutar sobre estos dispositivos aplicaciones JAVA desarrolladas con las plataformas disponibles de desarrollo: edición estándar (J2SE) o edición empresarial (J2EE). Así, CLDC define un conjunto mínimo de paquetes y clases JAVA y una serie de funciones esenciales de la máquina virtual de JAVA, de forma que las aplicaciones desarrolladas bajo esta base se puedan ejecutar con los recursos disponibles en los dispositivos móviles.
Para hacernos una idea de las necesidades computacionales relacionadas con la ejecución de programas en JAVA, la ejecución del programa HolaMundo sobre una plataforma Windows requiere unos 16 MB de memoria. Hemos de considerar que la versión 1.1 del CLDC está pensada para dispositivos que cuenten con entre 160 y 512 KB de memoria para la plataforma JAVA. Por tanto, para que las aplicaciones JAVA puedan ejecutarse en dispositivos de reducida capacidad, CLDC define un conjunto de requisitos mínimos para la máquina virtual, e implementación específica para clases básicas que aseguren que no se excedan los recursos disponibles de los dispositivos en que se instalarán.
A parte de la capacidad de almacenamiento, CLDC no hace más suposiciones sobre el tipo de plataforma en que debe ejecutarse. Por ejemplo, no asume ningún tipo de dispositivo de entrada o salida, ni precisa de ningún tipo de almacenamiento local para la ejecución de la aplicación. Estas características quedan como responsabilidad de cada fabricante de dispositivos. Aquí entran en juego los perfiles de J2ME, que añaden recursos adicionales disponibles para la mayoría de los dispositivos móviles. Además, minimizar el número de requisitos de CLDC permite aumentar el número de plataformas en que puede usarse. Quizás la única suposición que CLDC hace (obvia, por otra parte) se refiere a la existencia de un sistema operativo que pueda ejecutar y gestionar la máquina virtual. La especificación completa de CLDC puede encontrarse en http://jcp.org/jsr/detail/30.jsp. Otra página interesante de SUN, donde se pueden obtener los fuentes necesarios para trabajar con CLDC es http://java.sun.com/products/cldc.
En realidad, la especificación de CLDC indica qué características de la máquina virtual completa de JAVA no se usan para los dispositivos móviles. Sun proporciona una implementación de referencia de la especificación CLDC, denominada KVM (Kilo virtual machine). Por ser esta máquina virtual de libre disposición será la usada para trabajar en el curso. Se explicarán sus características de forma independiente a cualquier perfil, aunque normalmente no se usará esta máquina virtual de forma aislada, sino mediante alguna herramienta que integre la configuración y el perfil deseado.
También hemos de ser conscientes de la enorme rapidez con que evoluciona esta especificación y todo lo que sobre ella se construye. Por ejemplo, las versiones de CLDC se han sucedido rápidamente hasta ahora: la actual es la 1.1. Esta última ha incorporado, por ejemplo, la posibilidad de tratamiento de valores en coma flotante, algo no permitido en versiones previas.
Para poder compilar y ejecutar aplicaciones con la máquina virtual de CLDC (de la versión de SUN: KVM), debemos descargar e instalar las siguientes herramientas:
¿Cuándo interesa trabajar directamente con la
herramienta CLDC? Cuando queremos probar la ejecución de
programas simples que no necesitan de capacidades gráficas.
Recordemos que CLDC aporta las características básicas de
la máquina virtual. Por tanto, se puede usar para probar la
lógica del programa, usando para depuración trazas de
salida que se mostrarán por la línea de comandos. Esto tiene
la ventaja de poder trabajar de forma rápida sin necesidad de
disponer de un emulador de dispositivos móviles.
Ya tenemos instalada la versión adecuada de CLDC. Para poder
usarla hemos de definir una serie de variables de entorno, tal y como
se indica a continuación:
¿Sabe todo el mundo definir el valor de una variable de entorno? En la shell que usamos se hace de la siguiente forma:
set JAVA_HOME = (/fenix/depar/ccia/Java/jdk) set CLDC_HOME = ($HOME/java) set CLDC_PATH = ($CLDC_HOME/j2me_cldc) set CLDC_EXE = ($CLDC_PATH/bin) set EJEMPLOS = ($HOME/ejemplos)
Se recomienda copiar estas lineas e incluirlas en el archivo .login, ubicado en vuestro directorio raíz. Una vez hecho, para activar el valor de estas variables de entorno, ejecutad el comando: source .login.
Veamos un primer ejemplo de programa para la máquina virtual kvm. Se trata de un programa muy simple que sólo contiene como sentencia una salida por pantalla de un mensaje cualquiera. El código puede verse a continuación:
public class MensajePorPantalla{
public static void main ( String args[]){
System.out.println("Primer programa para kvm");
}
}
Para ganar tiempo, descargad el código de este ejemplo. Guardadlo en el directorio ejemplos: MensajePorPantalla.java
El texto de este primer programa puede escribirse usando cualquiera de los programas de edición disponibles en JAVA. Quizás uno de los más usados sea kwrite. Se puede configurar esta herramienta para que se produzca resaltado del texto, teniendo en cuenta la sintaxis de diversos lenguajes de programación. Suponemos que se han definido todas las variables de entorno previamente indicadas. También que el código del programa se encuentra almacenado en un archivo denominado MensajePorPantalla.java. Así mismo, estaremos en el directorio ejemplos que hemos ubicado en el directorion $HOME. Para proceder a la compilación del código se realizarán los siguientes pasos:
javac -bootclasspath $CLDC_EXE/common/api/classes -d ./tmpclasses MensajePorPantalla.java
Como resultado de esta operación se habrá generado un archivo denominado MensajePorPantalla.class ubicado en el directorio tmpclasses. Las opciones indicadas al compilador tienen el siguiente significado:
Una vez realizada la compilación, es necesario realizar una verificación de las clases generadas. Para ello se usa el comando:
$CLDC_EXE/linux/preverify -classpath $CLDC_EXE/common/api/classes:./tmpclasses -d ./tmpclasses MensajePorPantalla
Este comando se encarga de verificar que la clase generada realmente se ajusta a la especificación de CLDC. Ahora ya se puede ejecutar la aplicación, mediante el comando siguiente (suponemos en todo instante que todas las operaciones que se han realizado han sido ejecutadas estando posicionados en el directorio $EJEMPLOS):
$CLDC_EXE/linux/kvm -classpath ./tmpclasses MensajePorPantalla
Como resultado de esta ejecución, en línea de comando, habrá aparecido el mensaje:
Primer programa para kvm
Se puede comprobar la posibilidad de manejar números en coma flotante mediante la versión 1.1 de CLDC. Para ello podemos compilar y ejecutar el siguiente ejemplo:
public class Flotante{
public static void main(String args[]){
float a,b,c;
a=3.4f;
b=9.4f;
c=a/b;
System.out.println("División: "+c);
}
}
Descargad el código del enlace Flotante.java y realizad todos los pasos necesarios para poder ejecutarlo con la máquina virtual de CLDC, tal y como hemos hecho con el ejemplo anterior. El resultado a obtener debe ser:
División: 0.36170214
Para superar la limitación de recursos de los dispositivos para los que está pensada esta configuración, la librería de clases de CLDC es muy reducida. Consta de un paquete que contiene específicamente funcionalidad para J2ME, así como una selección de clases de los siguientes paquetes de la versión estándar de JAVA (aunque obviamente modificados):
Todas las posibles configuraciones consideradas en J2ME, así como todos los perfiles, contienen paquetes o clases de J2SE (versión estándar de Java). Cuando J2ME incorpora paquetes o clase de J2SE se han de verificar ciertas reglas:
Debido al uso de estas reglas, los paquetes y clase de J2ME siempre serán un subconjunto de los paquetes y clases de J2SE y además, los usuarios de J2SE no encontrarán sorpresas al usar J2ME. Describiremos a continuación los detalles de los paquetes incorporados de J2SE.
El paquete java.lang de CLDC contiene aproximadamente la mitad de las clases de las contenidas en el paquete de J2SE y algunas de las clases incorporadas no contienen su funcionalidad completa. Se indican a continuación las principales limitaciones:
|
Nombre de la Propiedad
|
Significado
|
Ejemplo
|
| microedition.configuration |
El nombre de la configuración J2ME que
la plataforma admite, junto con su número de versión.
|
CLDC-1.1 |
| microedition.encoding |
La codificación de caracteres predeterminada
que el dispositivo admite. No se requiere que los dispositivos ofrezcan
codificaciones
extram pero los fabricantes pueden incorporarlos si así lo
desean.
Si se hace, no habrá forma de determinar qué
codificaciones
están disponibles
|
ISO-8859-1 |
| microedition.platform |
El nombre de la plataforma o dispositivo. Un posible
valor específico podría ser j2me.
|
generic |
| microedition.profiles |
Indica los perfiles J2ME que el dispositivo admite,
separados por comas. Ya que la máquina virtual por defecto no
proporciona
ningún perfil, se devolverá NULL como valor para esta
propiedad. Un posible valor de devolución sería MIDP-2.0 |
MIDP-2.0 |
A continuación se incluye un ejemplo (Propiedades.java) para ver la forma en que se pueden obtener estas propiedades.
public class Propiedades {
// Se define el conjunto de propiedades a
// obtener
private static final String[] properties = {
"microedition.configuration",
"microedition.encoding",
"microedition.platform",
"microedition.profiles"
};
public static void main(String[] args) {
// No es posible una recuperación en conjunto
for (int i = 0; i < properties.length; i++) {
// Recuperación individual del valor de cada
// propiedad
System.out.println(properties[i] + " = " +
System.getProperty(properties[i]));
}
}
}
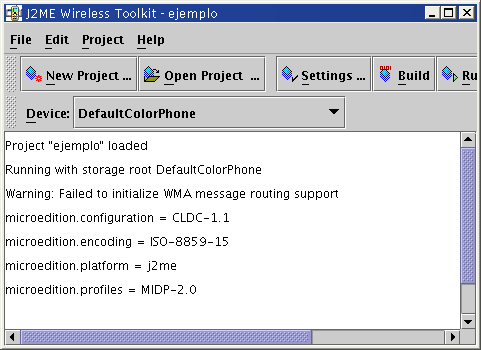
El resultado de ejecutar este programa es:
microedition.configuration = CLDC-1.1
microedition.encoding = ISO-8859-1
microedition.platform = generic
microedition.profiles =
Sin embargo, si este mismo programa se ejecuta mediante el entorno integrado, los resultados varían:
Básicamente este paquete incluye clases relacionadas con la gestión de fechas y horas.
CLDC proporciona sólo un reducido conjunto de la funcionalidad de este paquete en la versión estándar. Hay que considerar que la codificación de caracteres que puede conseguirse mediante estas clases es completamente dependiente de la plataforma.
Este paquete, no heredado de J2SE (versión estándar de Java) contiene una colección de interfaces que definen el Marco Genérico de Conexión (Generic Connection Framework). Este marco deberá ser usado por los perfiles desarrollados sobre CLDC, para proporcionar un mecanismo común para acceder a los recursos de red.
Para proporcionar facilidades de depuración, la máquina virtual debe ofrecer determinados recursos para que los depuradores puedan fijar puntos de ruptura, inspeccionar y modificar el valor de objetos, etc. La plataforma de Java 2 define una arquitectura (JPDA: Java Platform Debugger Architecture) que fija las características de depuración que una máquina virtual debe ofrecer. Los componentes lógicos que componen esta arquitectura se indican a continuación.
En esta arquitectura el depurador interactúa con la máquina virtual usando un protocolo denominado JDWP (Java Debug Wire Protocol). Este protocolo especifica los mensajes que se intercambiarán un cliente y un servidor, para hacer peticiones a la máquina virtual y para notificar al depurador los cambios producidos en la máquina virtual.
En este sentido, se entiende por cliente la parte de la arquitectura encargada de comunicarse con el depurador, quien efectúa peticiones a la máquina virtual. Por servidor nos referiremos a la parte dedicada a comunicarse directamente con la máquina virtual. La arquitectura general del sistema puede observarse en el esquema siguiente:
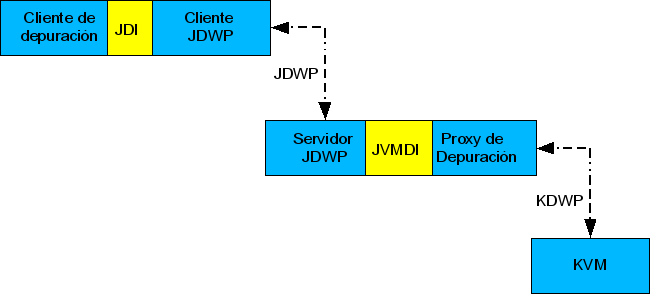
Mediante esta arquitectura se separan el depurador y la máquina virtual, que sólo han de respetar el protocolo común de comunicaciones. Esa es la función del servidor y del cliente de JDWP. Esta capa es la encargada de mapear los mensajes para y desde las interfaces de programación propias del depurador y de la máquina virtual. Para que se puedan acomodar diferentes máquinas virtuales o implementaciones de depuración, aunque cada una de ellas ofrezca su propia implementación de JDWP, se definen dos interfaces de programación internas:
Hay que tener en cuenta que la especificación de CLDC no ofrece funcionalidad para depuración. Sin embargo, una implementación práctica requiere la disponibilidad de esta facilidad. Por tanto, KVM debe ofrecer capacidad de depuración, pero por su limitación de recursos impide ofrecer una implementación completa de la funcionalidad requerida por el servidor de JDWP. Esto hace necesaria la existencia de una nueva capa software: KVM Debug Proxy. La función de esta capa es implementar las características de depuración que resultan demasiado costosas desde un punto de vista computacional. Así, el proxy de depuración no se ejecutará en el mismo lugar que la máquina virtual, por lo que no consume sus recursos. Lo normal es que este proxy se ejecute en otro sistema distinto y se comunicará con la máquina virtual mediante una variante de JDWP especialmente diseñada: KVM Debug Wire Protocol (KDWP), que sólo precisa una conexión vía socket.
De esta forma, el depurador no necesita conocer que realmente se está comunicando con un proxy de depuración, en lugar de con la máquina virtual en sí, ni de que normalmente no se ejecutará, siquiera, en la misma máquina en que se ejecuta el proxy de depuración.
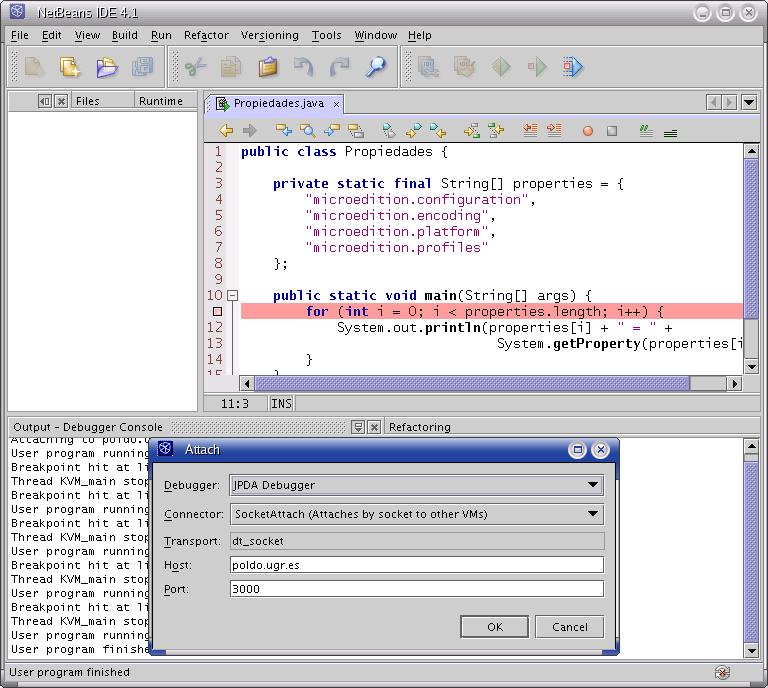
Visto todo esto, veamos cómo se llevaría a cabo la depuración de una aplicación para CLDC. Supondremos, como antes, que el código a depurar se encuentra en el directorio $EJEMPLOS. Se explicará cómo hacer la depuración sobre la clase Propiedades.java. Se precisan los siguientes pasos:
javac -g -bootclasspath $CLDC_EXE/common/api/classes -d tmpclasses Propiedades.java
$CLDC_EXE/linux/preverify -classpath $CLDC_EXE/common/api/classes:./tmpclasses -d . Propiedades
$CLDC_EXE/linux/debug/kvm_g -classpath . -debugger -port 2000 Propiedades
java -classpath $KDP_CLASSPATH kdp.KVMDebugProxy -l 3000 -p -r localhost 2000 -cp $ALL_CLASSES
netbeans
Aquí se explicarán cuestiones relativas a dos aspectos avanzados de uso de CLDC: cómo mejorar la forma en que la máquina virtual hace la carga de las clases a ejecutar y la forma de incorporar código nativo (no JAVA) en las aplicaciones desarrolladas. Para ellos hemos de tener en cuenta diferentes cuestiones.
En un sistema JAVA basado en la plataforma estándar, las clases básicas de JAVA se almacenan en un archivo llamado rt.jar y se cargan y enlazan de forma dinámica bajo demanda, a partir del momento en que la máquina virtual comienza su ejecución. Esta forma de proceder conlleva dos consecuencias de especial relevancia si se considera el caso de los dispositivos móviles:
Para afrontar estos problemas, KVM usa una técnica denomina preenlazado o también ROMizing. Esta técnica supone preprocesar las clases básicas de la plataforma, integrándolas en una imagen compacta, en la que aparecen ya cargadas y enlazadas, junto con la propia máquina virtual. Esta imagen se pasa a la ROM de los dispositivos móviles. De esta forma, cuando la máquina virtual se inicia, tiene disponibles las clases básicas, evitando así el retraso de tiempo debido a las tareas de carga y enlazado de las clases básicas. Este proceso se lleva a cabo durante la generación de la máquina virtual, y se encarga de ello una herramienta denominada JavaCodeCompact.
Lo ideal es integrar las propias clases de la aplicación en esta imagen, de forma que ya estarán precargadas en el momento en que la máquina virtual comienza a ejecutar. Para poder hacer esto, hemos de comprender la forma en que el proceso de preenlazado se lleva a cabo:
Para incluir además cualquier clase que deseemos en el código de la máquina virtual se pueden seguir dos procedimientos:
La primera de estas soluciones es la recomendada cuando se trata de desarrollos de cierta extensión, ya que mantiene mejor la separación entre el código virtual y las clases de la aplicación a incorporar. Sin embargo, para probar el procedimiento, utilizaremos el camino más corto. Para ello, vamos a generar de nuevo la máquina virtual de CLDC, pero incorporando a ella la clase encargada de detectar las propiedades (clase usada antes, Propiedades.java). Para ello, lo primero que haremos será copiar este archivo en el directorio que contiene el código fuente de las librerías básicas de CLDC. Es decir, se copiará al directorio $CLDC_PATH/api/src. Una vez copiado el archivo de la clase a añadir, haremos lo siguiente:
cd $CLDC_PATH/kvm/VmUnix/build
./kvm Propiedades
En realidad la máquina virtual no incorpora la interfaz JNI (Java Native Interface), por lo que no es posible incorporar en las aplicaciones código escrito en C y cargar las clases correspondientes en tiempo de ejecución. La única forma de poder usar clases en que se han incluido métodos escritos en C es incorporar estas clases a la propia máquina virtual, como hemos visto anteriormente. Evidentemente esta opción sólo es posible cuando se dispone de control absoluto sobre la propia máquina virtual.
Veamos un ejemplo completo de todo este proceso. El primer paso consistirá en determinar qué métodos serán los que se implementen en código nativo. Haremos una clase muy sencilla que escribe la hora o la fecha, en función de un argumento de entrada (H o T). Los métodos nativos a usar son los que obtienen e imprimen estos datos. Supongamos que los métodos escritos en código nativo son imprimeHora e imprimeFecha. El archivo java resultante sería el siguiente (Nativo.java):
public class Nativo {
// Definicion de los métodos nativos
public native void imprimeHora();
public native void imprimeFecha();
// Método main
public static void main(String args[]){
char letra;
if (args.length == 0)
System.exit(0);
else{
letra=args[0].charAt(0);
switch(letra){
case 'H':
case 'h': new Nativo().imprimeHora();
break;
case 'M':
case 'm': new Nativo().imprimeFecha();
break;
default: System.exit(0);
}
}
}
}
Una vez que hemos escrito el código de la clase, se compilará y preverificará tal y como ya se comentó con anterioridad. Además, la clase que contiene código nativo se comprimirá en un archivo jar.
javac -bootclasspath $CLDC_EXE/common/api/classes -d tmpclasses Nativo.java
$CLDC_EXE/linux/preverify -classpath $CLDC_EXE/common/api/classes:./tmpclasses -d . Nativo
Esto deja el archivo Nativo.class en el directorio desde el que se ejecuta el comando anterior. Hay que observar que en este momento aún no hay necesidad siquiera de disponer de la implementación de los dos métodos nativos.
Ahora correspondería dar la implementación de los métodos que imprimen la fecha y la hora. Pero hemos de tener en cuenta lo siguiente: en realidad, lo que vamos a hacer es proporcionar directamente el código C asociado a estos métodos. Es decir, estamos sustituyendo de forma manual el método de construcción de la propia máquina virtual. En realidad, cuando se compilan los archivos fuente de la máquina virtual lo que se está haciendo es esto. Pero hay una cuestión importante: ¿qué criterio de nomenclaturas se sigue en el proceso de construir el archivo C que, en última instancia, dará lugar a la máquina virtual? Porque en dicho archivo habrá que asociar, de alguna manera, los métodos y las clases a las que pertenecen. Es decir, al construir la máquina virtual se produce una asociación entre el código de las clases y el código C que implementa la máquina virtual. Así, la ejecución de un método de una clase da lugar a la ejecución de un método específico (en C) que lo implementa. Al hacerlo de forma manual, nosotros construiremos un archivo de código C que dará la implementación de los métodos imprimeHora e imprimeFecha, teniendo en cuenta que ambos pertenecen a la clase Nativo.
La forma más sencilla de obtener los nombres es usar la clase de utilidad ImprimeNombreMetodoNativo (que habrá que compilar con el compilador de JAVA de la versión estándar).
Hay que ejecutar dicha clase, pasando como argumento la clase Nativo.java, anteriormente vista, para ver el nombre JNI de cada uno de los métodos en la versión C que constituye la máquina virtual. La salida sería:
java ImprimeNombreMetodoNativo Nativo imprimeHora
Java_Nativo_imprimeHora
java ImprimeNombreMetodoNativo Nativo imprimeFecha
Java_Nativo_imprimeFecha
En el caso en que los métodos tuvieran argumentos, el nombre JNI ha de considerarlos. Para ello, en primer lugar usaríamos el comando javap
javap -s Nativo
La salida obtenida es la siguiente:
Compiled from "Nativo.java"
public class Nativo extends java.lang.Object{
public Nativo();
Signature: ()V
public native void imprimeHora();
Signature: ()V
public native void imprimeFecha();
Signature: ()V
public static void main(java.lang.String[]);
Signature: ([Ljava/lang/String;)V
}
Pues bien, el prototipo de los métodos se incluye entre paréntesis, en la línea de abajo. Así, si quisiera saber el nombre JNI del método main, usaría la clase ImprimeNombreMetodoNativo, pasando como argumento la última línea de la salida anterior.
java ImprimeNombreMetodoNativo Nativo main "([Ljava/lang/String;)V"
Java_Nativo_main___3Ljava_lang_String_2
Ahora tendríamos que escribir las funciones en sí. En el caso nuestro es sencillo, ya que no hay argumentos de entrada ni de salida. Como sólo estamos interesados en mostrar esta funcionalidad, y no describirla de forma completa, completaremos el ejemplo de esta forma y se harán algunos comentarios finales sobre la forma de pasar argumentos de entrada y devolver valores de salida. El código en C será el siguiente (archivo (NativoEjemplo.c)):
#include#include
El procedimiento que seguiremos consistirá en conseguir enlazar la clase Nativo (incompleta en realidad al no dar implementación de algunos métodos) con la implementación C de los mismos, e incorporar la clase Nativo a la máquina virtual, igual que hicimos previamente con la clase Propiedades. Para ello, los pasos a seguir son:
SRCFILES = cache.c class.c fields.c frame.c garbage.c $(COLLECTOR) \
global.c interpret.c execute.c loader.c main.c native.c \
property.c thread.c nativeCore.c loaderFile.c hashtable.c \
verifier.c log.c jar.c inflate.c stackmap.c profiling.c \
pool.c runtime_md.c StartJVM.c \
nativeFunctionTableUnix.c events.c resource.c \
verifierUtil.c NativoEjemplo.c
cd $CLDC_PATH/build/linux
make clean
make
cd $CLDC_PATH/kvm/VmUnix/build
./kvm Nativo h (La salida es: 1:11:42)
./kvm Nativo m (La salida es: 19 del 9 de 2005)