
Autor: F. Javier García Castellano
Web: http://decsai.ugr.es/~fjgc, Mail: fjgc@decsai.ugr.es



(C) GeNeura Team
Web: http://geneura.ugr.es, Mail: tutti@geneura.ugr.es
| Parsers XML
Autor: F. Javier García Castellano Web: http://decsai.ugr.es/~fjgc, Mail: fjgc@decsai.ugr.es |
(C) GeNeura Team Web: http://geneura.ugr.es, Mail: tutti@geneura.ugr.es |
Un parser o procesador o analizador sintáctico lee el documento XML y verifica que es XML bien formado , algunos también comprueban que el código XML sea válido.
El parser o procesador de XML es la herramienta principal de cualquier aplicación XML. Mediante el parser no solamente podemos comprobar si nuestros documentos son bien formados o válidos, sino que también podemos incorporarlos a nuestras aplicaciones, de manera que estas puedan manipular y trabajar con documentos XML.
Podemos dividir los parsers XML en dos grupos principales:
En el caso de utilizar un DTD, es preferible utilizar un parser con validación.
Normalmente no nos tendremos que preocupar de buscar un parser concreto para comprobar la validez de nuestros documentos XML, ya que los desarrolladores de las aplicaciones que utilizaremos como navegadores o visualizadores o transformadores de esos documentos en el documento final que el usuario ve, incluirán sus propios parsers. Un ejemplo de esto es el caso del Microsoft Internet Explorer 5 (o superior), que utiliza el parser de MS (incluido en la librería MSXML.DLL); o el caso de Mozilla, que internamente utiliza el parser EXPAT (escrito en C).
A continuación teneis un parser sin validación escrito en JavaScript. Presenta el árbol del documento a comprobar.
Teclea o copia el código XML aquí y pulsa en "Procesar"
Para extraer la información que contiene un documento XML, se podría escribir código para analizar el contenido del archivo XML, pues no deja de ser un archivo de texto, tal y como lo podríamos hacer con HTML. Sin embargo, esta solución no es muy aconsejable y desaprovecharía una de las ventajas de XML: el ser una forma estructurada de representar datos.
La mejor forma de recuperar información de archivos XML es utilizar un parser de XML, que sea compatible con el modelo de objeto de documento (DOM) de XML. DOM define un conjunto estándar de comandos que los parsers devuelven para facilitar el acceso al contenido de los documentos XML desde sus programas. Un analizador de XML compatible con DOM toma los datos de un documento XML y los expone mediante un conjunto de objetos que se pueden programar.
DOM para XML es un modelo de objetos estándar (propuesto por el W3C) que muestra el contenido de un documento XML. La Especificación del Modelo de Objeto de documento (DOM) del W3C define actualmente lo que debería mostrar un DOM como propiedades, métodos y eventos.
En http://www.asptutor.com/xml/index5.asp puedes ver una introducción de como se haría en Visual Basic, en http://java.sun.com/webservices/docs/1.1/tutorial/doc/JAXPDOM.html#wp66050como poder hacerlo con JAVA, en http://search.cpan.org/src/ENNO/libxml-enno-1.02/html/XML/DOM.html como hacerlo con Perl, en http://expat.sourceforge.net como hacerlo en C y en C++ usando expat (el parser del Mozilla) y en http://msdn.microsoft.com/msdnmag/issues/01/01/xml/default.aspx como hacerlo en C# .NET
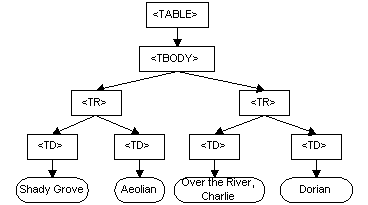
Veamos un ejemplo, supongamos el siguiente trozo de código XML:
<TABLE>
<TBODY>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</TBODY>
</TABLE>
El DOM representaría esta tabla de la siguiente forma:
En este apartádo vamos a ver como trabajar con el Modelo de Objeto Documento (DOM) usando Perl, para los que no sepan Perl en http://flanagan.ugr.es/perl hay un tutorial en castellano de Perl y en http://decsai.ugr.es/~fjgc/dbi/modulos.htm como instalar módulos en perl.
Para manejar el DOM bajo Perl vamos a utilizar el módulo XML::DOM que lo podeis encontrar en http://search.cpan.org/search?dist=libxml-enno. El módulo XML::DOM se basa en el módulo XML::Parser y éste a su vez en la librería del expat (parser de libre distribución del Mozilla). Para consultar los métodos y objetos del módulo XML::DOM podeis mirar en http://theoryx5.uwinnipeg.ca/CPAN/data/libxml-enno/XML/DOM.html.
Para comprender mejor como se trabaja con el DOM en Perl, vamos a a usar el siguiente documento XML de ejemplo:
<?xml version="1.0" standalone="yes"?>
<noticias>
<!--Noticia 1 -->
<noticia tipo="economia">
<titulo url="http://www.elpais.es/articulo.html?anchor=elpepieco&xref=20010215elpepieco_14&type=Tes&d_date=20010215">
Microsoft, investigado por invertir en un rival
</titulo>
<fecha>15 de febrero de 2001</fecha>
<contenido>
El gigante de la informatica Microsoft, pendiente
de una apelacion para evitar ser dividido en dos por
vulnerar la competencia, está siendo investigado otra vez por las autoridades
antimonopolio, que sospechan de por que el mayor fabricante de programas invirtio
135 millones de dolares (24.165 millones de pesetas) en su rival Corel.
</contenido>
</noticia>
<!--Noticia 2 -->
<noticia tipo="internet">
<titulo url="http://www.abc.es/Internet/noticia.asp?id=13298&dia=18022001">
Clinicas reales y virtuales para tratar adictos a Internet
</titulo>
<fecha>18 de febrero de 2001</fecha>
<contenido>
La aparicion de una nueva patologia, la "dependencia" a internet, esta confirmada por la creacion
de numerosas clinicas en Estados Unidos, reales o virtuales, para tratar de remediar las
enfermedades de la red....
</contenido>
</noticia>
</noticias>
En el ejemplo anterior se tiene un documento XML que está pensado para trabajar con noticias que aparecen en Internet. Lo que vamos a hacer es, usando Perl y el módulo XML::DOM, un programa que procese el documento xml y muestre el titulo de las noticias
#!/usr/bin/perl
#Indicamos al perl que use el modil XML::DOM
use XML::DOM;
#Creamos un parser XML
$parser = new XML::DOM::Parser;
#Hacemos el parser XML al fichero ejmploDOM.xml y obtenemos el DOM
$doc = $parser->parsefile ("ejemploDOM.xml");
# Cogemos el titulo todas las noticias del documento XML
$noticias = $doc->getElementsByTagName ("titulo");
#Cogemos el número de noticias
$n = $noticias->getLength;
#Escribimos el título de cada noticia
for (my $i = 0; $i < $n; $i++)
{
#Cogemos el tiltulo de la noticia i
my $noticia = $noticias->item ($i);
#Imprimimos el nombre de la etiqueta
print $noticia->getTagName;
print ": ";
#Cogemos el hijo (texto) de la etiqueta que estamos procesando
my $noticia_contenido = $noticia->getFirstChild;
#Imprimimos el contenido del hijo
print $noticia_contenido->getData;
print "\n";
}
# Escribimos la salida del parser (el documento XML) en un fichero
$doc->printToFile ("salida.xml");
# Escribimos el documento XMl en pantalla
#print $doc->toString;
# Limpiamos la memoria ocupada por el documento XML
$doc->dispose;
Ahora vamos a hacer un segundo ejemplo donde mostraremos las noticias, y la url correspondiente
#!/usr/bin/perl
#Usamos el módulo XML::DOM de Perl
use XML::DOM;
#Creamos un parser XML
$parser = new XML::DOM::Parser;
#Hacemos el parser XML al fichero ejmploDOM.xml
$doc = $parser->parsefile ("ejemploDOM.xml");
# Cogemos los nodos del DOM cuyas etiquetas sean titulo
$noticias = $doc->getElementsByTagName ("titulo");
#Cogemos el número de noticias
$n = $noticias->getLength;
#Escribimos el título de cada noticia
for ($i = 0; $i < $n; $i++)
{
#Cogemos el tiltulo de la noticia i
$noticia = $noticias->item ($i);
#Imprimimos el nombre de la etiqueta
print $noticia->getTagName;
print ": ";
#Cogemos el hijo (texto) de la etiqueta que estamos procesando
my $noticia_contenido = $noticia->getFirstChild;
#Imprimimos el contenido del hijo
print $noticia_contenido->getData;
#Cogemos el valor del atributo url
$mi_url= $noticia->getAttributeNode("url");
#Imprimimos el contenido de dicho atributo
print " (href=";
print $mi_url->getValue;
print " )\n";
}
# Limpiamos la memoria ocupada por el documento XML
$doc->dispose;
Ahora vamos a hacer un tercer ejemplo donde recorremos el DOM
#!/usr/bin/perl
#Usamos el módulo XML::DOM de Perl
use XML::DOM;
#Creamos un parser XML
my $parser = new XML::DOM::Parser;
#Hacemos el parser XML al fichero ejmploDOM.xml
my $doc = $parser->parsefile ("ejemploDOM.xml");
#Cogemos el nodo raiz
my $raiz = $doc->getFirstChild;
#Como el nodo raiz está en lo alto de la jerarquía, ponemos profundidad =0
my $profundidad=0;
#Mostramos el árbol xml
muestra_arbol($raiz,$profundidad);
# Limpiamos la memoria ocupada por el documento XML
$doc->dispose;
#------------------------------------------------------------------------
sub muestra_arbol()
{
#Cogemos los dos parámetros el nodo del árbol y la profundidad
my ($nodo, $profundidad)=@_;
#Miramos el tipo de nodo, si es de texto (hoja del DOM) decimos que hay datos
if ($nodo->getNodeType==TEXT_NODE) {
for (my $i=0; $i < $profundidad; $i++) {print " "};
print $nodo->getData;
print "\n";
}
#Miramos el tipo de nodo, si es un comentario
elsif ($nodo->getNodeType==COMMENT_NODE) {
for (my $i=0; $i < $profundidad; $i++) {print " "};
print "COMENTARIO\n";
}
#No es nodo hoja, lo mostramos y recorremos sus hijos
else
{
#Nos vamos a la derecha dependiendo de la profundidad
for (my $i=0; $i < $profundidad; $i++) {print" "};
#Mostramos la etiqueta del nodo
print $nodo->getTagName;
print "\n";
#Cojemos los nodos hijos y el número que hay
my $hijos=$nodo->getChildNodes;
my $n=$hijos->getLength;
#Para cada nodo hijo, mostramos su etiqueta y mostramos su subarbol
for (my $i;$i < $n; $i++)
{
#Cogemos el hijo i
my $hijo=$hijos->item($i);
#Exploramos el subarbol del hijo i
muestra_arbol($hijo,profundidad+1);
}
}
}
#------------------------------------------------------------------------
Resumiendo, como podemos ver, con XML es mucho más fácil (dentro de lo que cabe) procesar la información que lo era antes con HTML, ya que para procesar una página HTML (no XHTML) teníamos que trabajar con ella como si fuera texto plano.
Ejercicio: Probar alguno de los códigos que se han escrito anteriormente en el parser XML on-line que teneis aquí. Probad como no funciona bien si el código XML está no está bien formado (Si es que no lo habeis probado anteriormente)
Ejercicio: Dibuja cual sería el DOM de uno de los documentos XML realizado en ejercicios anteriores (Escoge, por ejemplo, el ejercicio del hotel). Este ejercicio os ayudará a comprender cómo trabajan las aplicaciones sobre XML, y como manipulareis el árbol generado por un documento XML desde vuestra aplicación
Ejercicio:Coge el documento XML del ejercicio anterior y muestra el contenido de algún elemento del mismo, que se repita varias veces (si has cogido el ejemplo del hotel, que escriba los nombres de los hoteles>
Ejercicio:Coge el documento XML del ejercicio anterior y muestra el contenido de algún elemento del mismo, generando una página HTML. Basta que la página se vea por pantalla y luego podeis verla con el mozilla. (para guardar la salida por pantalla del ejemplo se haría de la siguiente forma: ejercicio.pl > pagina.html). Si sigues con el ejemplo de los hoteles que escriba una página html con los nombres de los hoteles.